MANUAL
JVoice2Text 取扱説明書
JVoice2Text は、マイク監視によるリアルタイム文字起こしと、WAVファイルの文字起こしを行う スタンドアロン音声文字起こし支援ツールです。ここでは、メイン画面・データ確認画面・音声ファイル文字起こし画面の使い方をまとめています。
クイックスタート
- メイン画面で必要に応じて入力デバイス、Whisperモデル、言語などを設定します。
- 文字起こし開始 を押すとマイク監視が始まり、音声を検知すると自動で録音・文字起こしします。
- 文字起こし結果は 最新文字化情報 に表示され、保存データは出力フォルダ配下に日付別・セッション別で保存されます。
- 過去データを確認したい場合は データ確認、既存のWAVファイルを文字起こししたい場合は 音声ファイル文字起こし を開きます。
主な保存先とファイル構成
録音データは、設定された 出力フォルダ の下に、日付ごとのフォルダ、その下にセッションごとのフォルダを作成して保存されます。
出力フォルダ/
YYYY-MM-DD/
session_YYYYMMDD_HHMMSS/
audio_YYYYMMDD_HHMMSS.wav
transcript_YYYYMMDD_HHMMSS.txt
speaker_00/
transcript_speaker_00_YYYYMMDD_HHMMSS.txt
speaker_01/
transcript_speaker_01_YYYYMMDD_HHMMSS.txt
音声ファイル文字起こし画面では、選択したWAVファイルと同じ場所に対応する transcript_*.txt がある場合、その内容を先に表示できます。
メイン画面
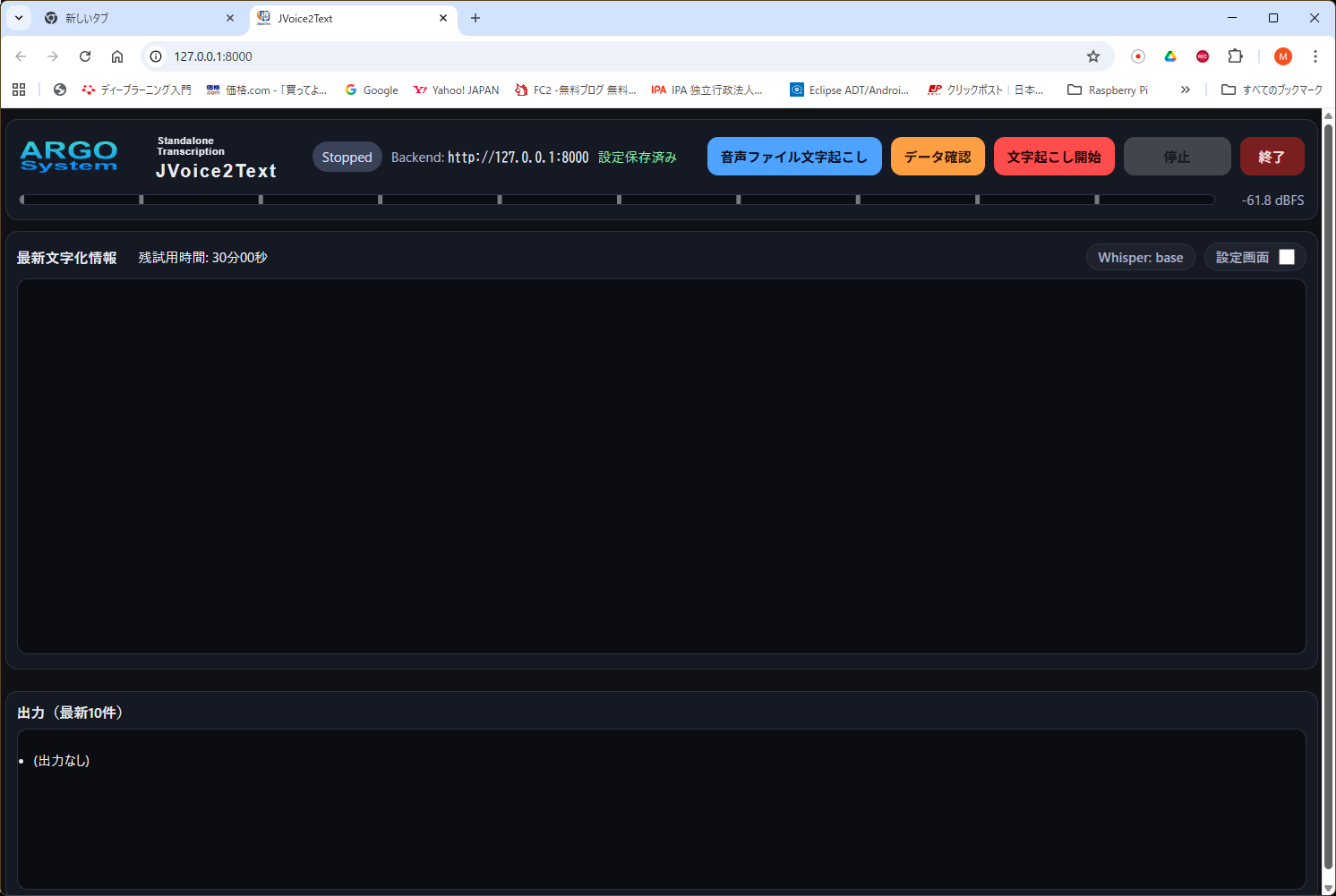
メイン画面(運用画面)
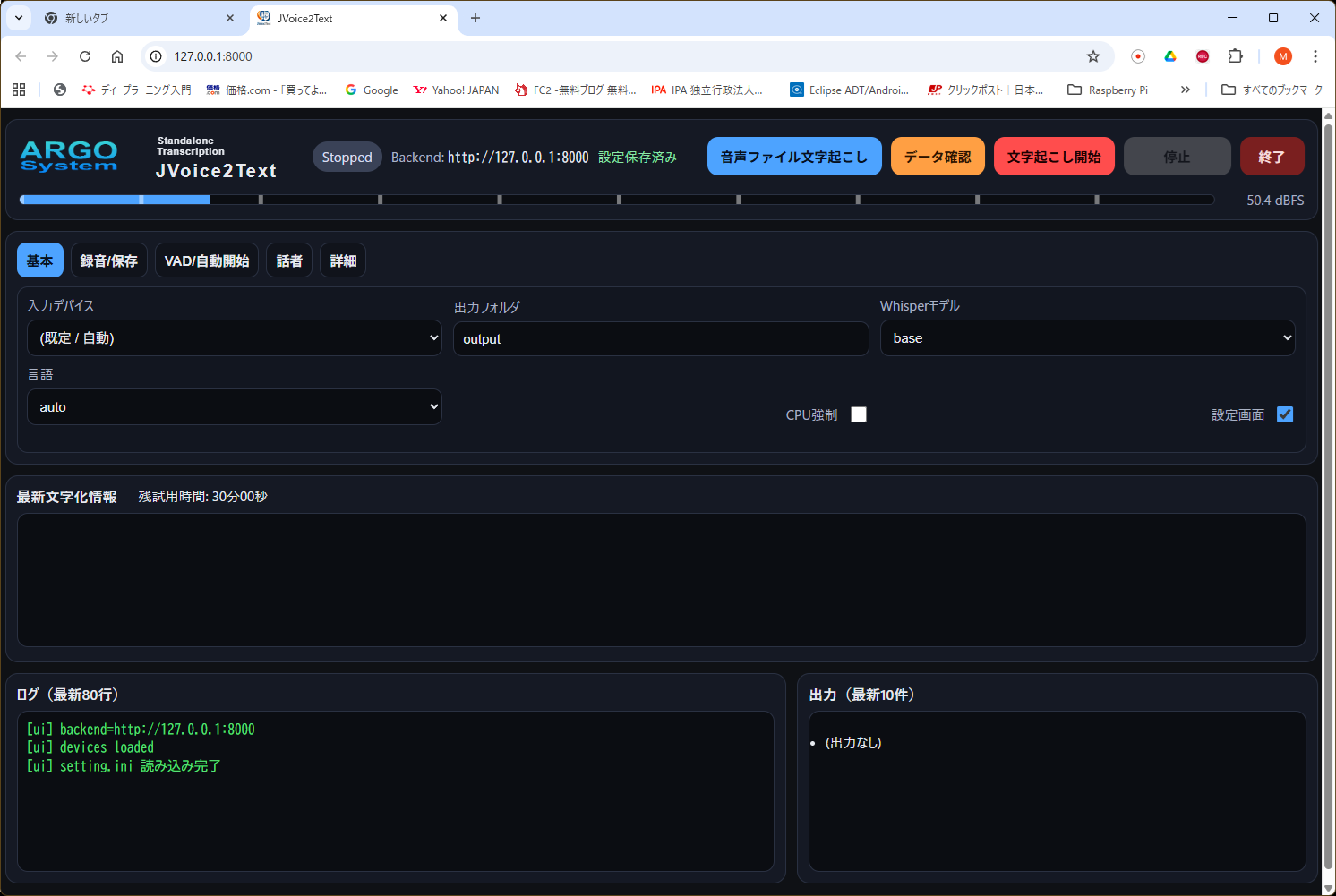
メイン画面(設定画面)
主な役割
マイク入力を監視し、音声を検知すると自動で録音・文字起こしを行う画面です。最新の文字起こし結果、ログ、保存済みセッション一覧を確認できます。
上部のボタン
- 音声ファイル文字起こし:WAVファイルを選択して文字起こしする専用画面を開きます。
- データ確認:保存済みのセッションを一覧表示する画面を開きます。
- 文字起こし開始:マイク監視を開始します。監視中は音声検知により録音と文字起こしが自動で行われます。
- 停止:監視を停止します。
- 終了:メイン画面を閉じ、連動するサブ画面も終了します。
表示項目
- Stopped / Monitoring:現在の動作状態を表示します。
- Backend:接続しているバックエンドURLを表示します。
- dBFSメーター:入力音量レベルの目安です。
- 最新文字化情報:最新セッションの文字起こし内容を表示します。表示されるのは要約ではなく、保存された文字起こしテキストです。
- ログ:最新80行を表示します。
- 出力:最新10件のセッションを表示します。
設定項目
| タブ | 主な設定 | 内容 |
|---|---|---|
| 基本 | 入力デバイス / 出力フォルダ / Whisperモデル / 言語 / CPU強制 / 設定画面 | 入力元、保存先、文字起こしモデル、言語などの基本設定です。 |
| 録音/保存 | 最短録音 / 停止無音 / 最大録音時間 / プリロール / 区間WAV保存 | 録音区間の長さや停止判定、事前取り込み秒数などを設定します。 |
| VAD/自動開始 | VAD強度 / VAD frame / 開始トリガ / 開始dB | 音声検知の厳しさや開始条件を設定します。 |
| 話者 | 話者数(固定) / 埋め込み最短 | 話者分離の目安となる設定です。 |
| 詳細 | キュー最大 | 処理待ち件数の上限です。 |
データ確認画面
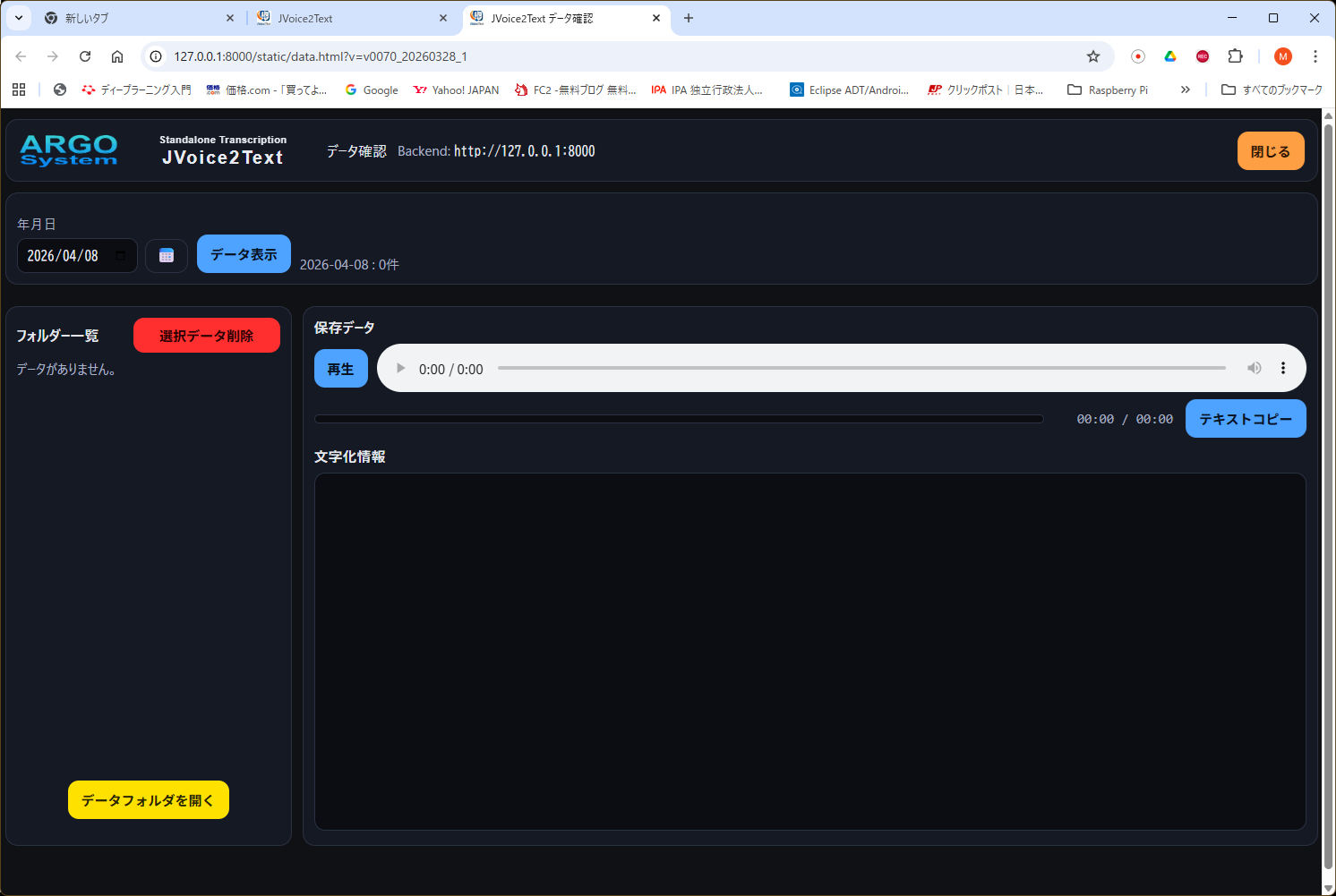
保存済みセッションの確認、再生、テキスト確認を行う画面です。
使い方
- 年月日 で確認したい日付を選択します。
- データ表示 を押すと、その日のセッション一覧が左側に表示されます。
- 一覧からセッションを選ぶと、右側に音声プレーヤーと文字化情報が表示されます。
- 再生 で選択音声を再生できます。
- テキストコピー で表示中の文字化情報をクリップボードへコピーできます。
補足
- 選択データ削除 は、当日データ以外を削除します。当日データは削除できません。
- データフォルダを開く は、出力フォルダをエクスプローラーで開きます。
- 文字化情報欄には、セッション内の最新の
transcript_*.txtが表示されます。
音声ファイル文字起こし画面
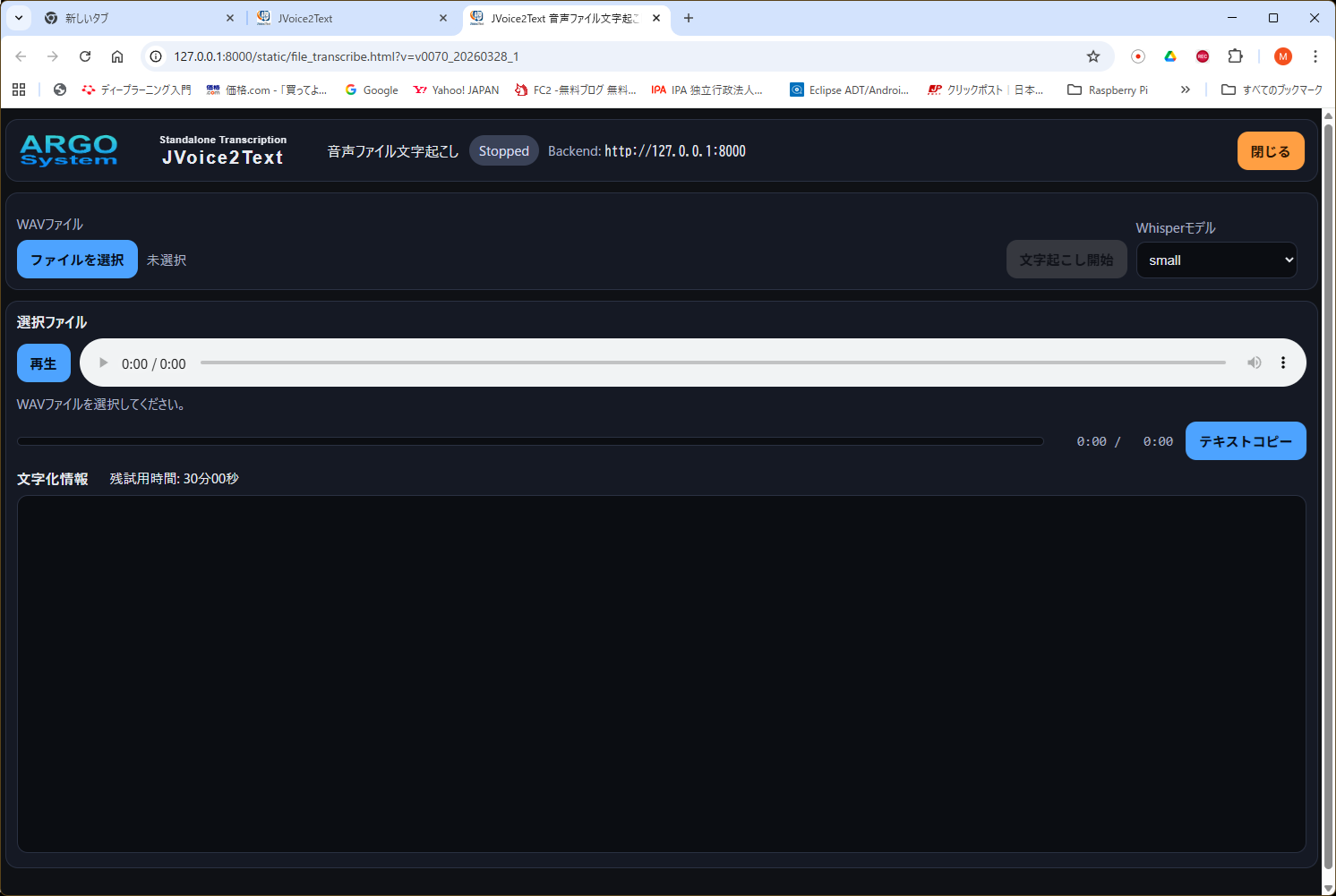
既存のWAVファイルを選択して文字起こしする専用画面です。
使い方
- ファイルを選択 を押してWAVファイルを選びます。
- 必要に応じて Whisperモデル を選択します。
- 文字起こし開始 を押すと処理を開始します。
- 処理中は 進捗率 と状態表示が更新されます。
- 完了すると文字化情報欄に結果が表示され、選択したWAVファイルの場所へテキストが保存されます。
補足
- 対応入力はWAVファイルです。
- 同名の文字起こしテキストが既に存在する場合は、上書き確認が表示されます。
- 監視中は音声ファイル文字起こしを開始できません。
- テキストコピー で表示内容をコピーできます。
About画面
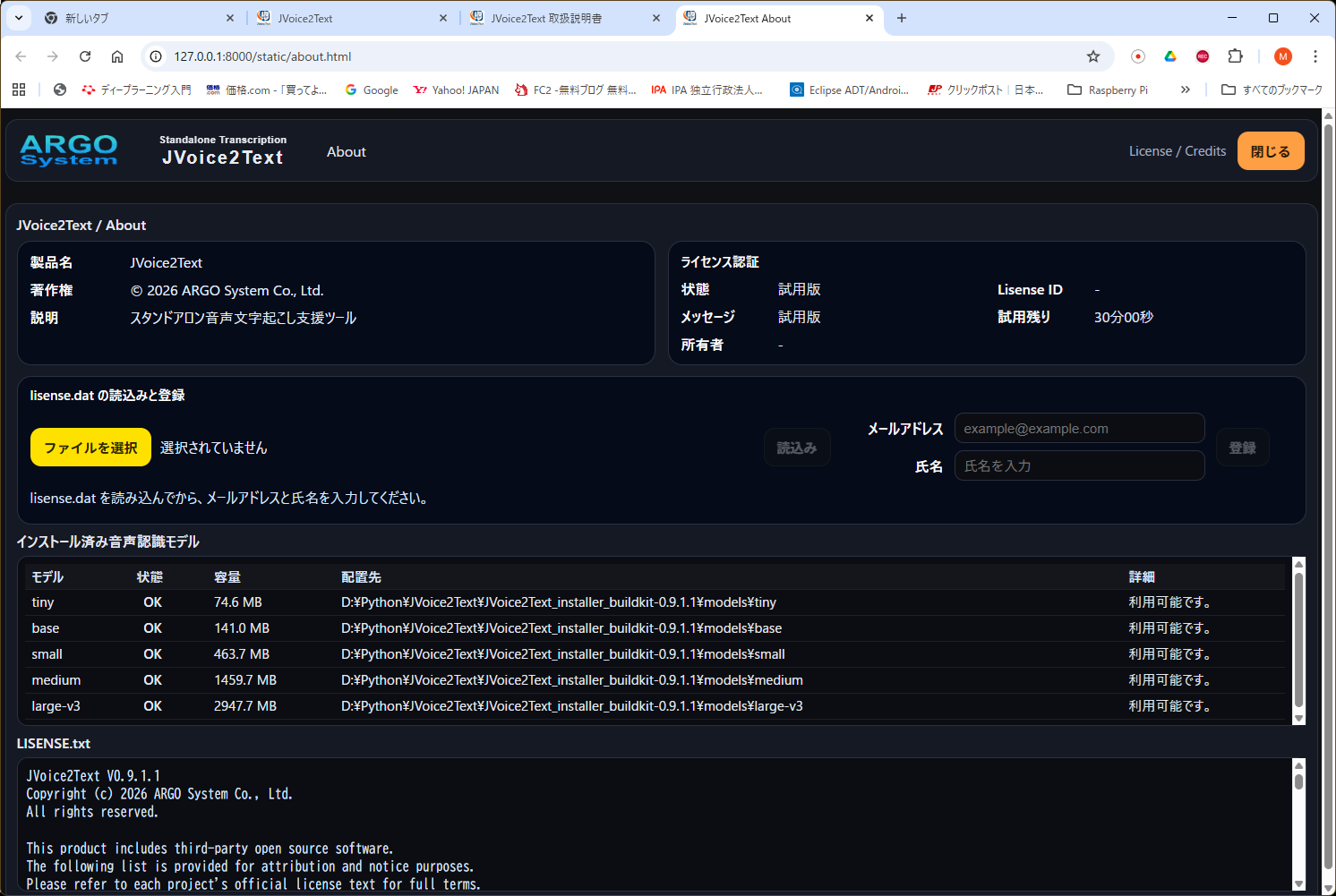
ライセンス情報、インストール済みモデル、LISENSE.txt を確認できます。
- lisense.dat の読込みと登録 からライセンスファイルを読み込めます。
- インストール済み音声認識モデル では tiny / base / small / medium / large-v3 の状態を確認できます。
- LISENSE.txt では著作権表記や第三者ソフトウェアのライセンス表示を確認できます。
注意事項
- 音声ファイル文字起こし画面は、処理中は閉じられません。
- Whisperモデルやデバイス設定によって、処理速度や必要メモリ量が変わります。
- 話者分離はセグメント単位で実施されます。環境によっては全て
speaker_00になる場合があります。 - 試用版では、試用時間は 文字起こし時間30分 です。